Whether you call it Personal Science, Self-Research or Quantified Self, many of us have questions about ourselves and try to find answers for them. It’s a process that can range from structured journaling to rigorous N-of-1 studies. It’s about you – and it can be about nearly anything. From introspection to data analysis, self-research can help people find what habits work for them, manage chronic conditions, and learn more about themselves.
In collaboration between Quantified Selfand Open Humans, we want to support self-research as a collective endeavor and provide a framework where a community of self-researchers can help each other. As one of the main support frameworks for this we have been hosting weekly self-research chats. In these chats you can share your currently on-going projects or projects you are currently planning; ask for feedback or advice; get help when you’re stuck; or brainstorm new ideas.
We started these calls last year as part of our collective memorial to Steven Keating. On July 19 2019 Steven – an inspiring advocate for patient data access – passed away. Curiosity was a driving force in Steven’s life. He recorded and shared videos of his brain surgery, explored his cancer’s genetic data, and printed 3D models of his tumor. Steven was also a supporter of Open Humans, and served as a director up until his passing. In his memory and in celebration of his life, we would like to help more people be curious about themselves. Our goal is to share reports about what we learned this July, in honor of him.
Our first memorial to Steven last year culminated in a Show & Tell meeting in which participants of the regular self-research chats presented their projects and what they learned from them. Given the large interest in this we will do the same this year: At the end of July we will organize another Show & Tell meeting in memory of Steven and just like last year we will hold weekly self-research meetings to prepare our projects.
We’re inviting you to join our calls – every Thursday at 10am Pacific time – to share your ideas about self-research projects – questions they have, and potential approaches – and provide support for each other in our efforts. Doing this in a group means you can get help when you’re stuck! This is an opportunity to try self-research for the first time – or to pursue a project you already have – by doing it with a small group of people who have diverse skills, lots of experience, and a desire to support you.
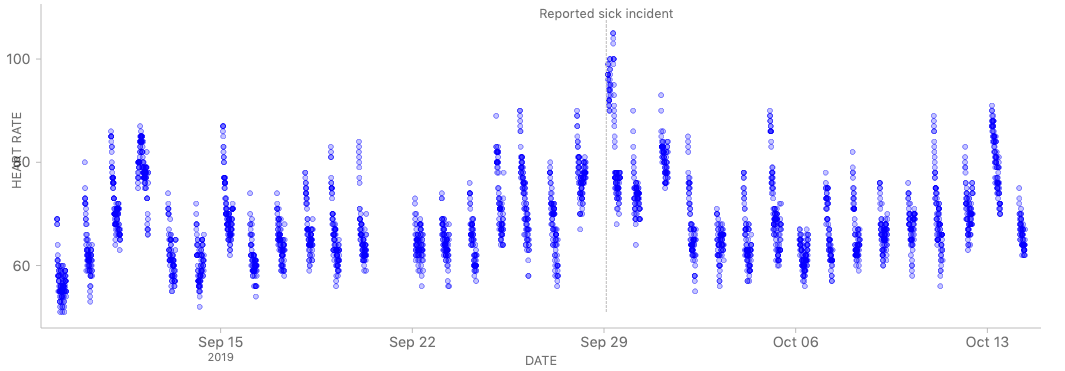
Do changes in physiological signals that are measured through wearables (such as body temperature and resting heart rate) precede consciously experienced symptoms (such as coughs, sore throats, shortness of breath, etc.)? This question is on many people’s minds right now, and it was a hot topic during an Open Humans community call in early March. Collectively we wondered whether it is possible to explore and potentially improve, through collective self research & an open process, what individual value data has with wearable data and symptom tracking.
As a result of this we have launched Quantified Flu, a collective project that tries to answer this question through both retrospective data analyses and the ongoing reporting of symptoms. It allows you to annotate your existing wearable data by adding past dates on which you fell sick. For the ongoing symptom collection, you can set up a daily check-in time on which you will get an email asking you to either quickly report “no symptoms” or enter symptoms if you experience any.
You can decide how much of this data you want to share: You opt-in to publicly share the data through a random identifier, allowing others to analyze that data and create new and improved data visualizations. In the long-run we might share aggregated and de-identified data as well, as long as we are confident that this respects individual privacy. If you are interested in joining this effort as a participant, head to Quantified Flu and sign up! All of this was made possible in such a short amount of time thanks to our great community, including Gary Wolf, Ernesto Ramirez, Katarzyna Wac, Chris Ball, Beau Gunderson, Lukasz Baldy, Konstantin Vdovkin and many more. If you want to contribute data visualizations, adding support for more wearables or help with web development, join our Slack and visit the #quantifiedflu channel!
Come to our Community Calls
As mentioned before: The idea to run Quantified Flu came directly out of our community calls, and given the huge interest in them we have ramped up the frequency and are now doing them on a weekly basis: They take place every Tuesday at 10am Pacific / 1pm Eastern / 6 pm GMT / 7pm CEST and you are invited to join us. We always welcome seeing new faces!
In case you missed it: we took notes & recorded our kickoff webinar for the Keating Memorial Self Research activity last week!
On Thursday we’ll have “open office hours” to offer free expert support for people getting started with questions and ideas about what they want to do. The meeting is at 10am PST / 6pm GMT on February 13 (Thursday).
Please feel welcome to join the videochat on Thursday! See this link for how to join (it’s also where we’ll take notes): https://tinyurl.com/uqw5gcl
You’re welcome to join the Keating Memorial Self Research activity at any time in coming months. (Although we think it’s ideal to start now!) Our support is staged (developing ideas, prototyping tools, data analysis) but we’ll be available throughout. Our goal is to complete projects and share what we learned no later than mid-July.
We’re inviting people to share their ideas about self-research projects – questions they have, and potential approaches – and provide support for each other in our efforts.
Doing this in a group means you can get help when you’re stuck! This is an opportunity to try self-research for the first time – or to pursue a project you already have – by doing it with a small group of people who have diverse skills, lots of experience, and a desire to support you.
To join:
Join the Keating Memorial Self Research activity on Open Humans
We’ll use this to send updates and reminders about upcoming stuff.
Post something:
… a self-research project you might want to do, a project you’re currently working on, something you already did, or just introduce yourself – say hi!
Anybody can do self-research! It can range from structured journaling to rigorous N-of-1 studies. It’s about you – and it can be about nearly anything. From introspection to data analysis, self-research can help people find what habits work for them, manage chronic conditions, and learn more about themselves.
Our goal is to start in February and to have completed our projects by July. What we learn will serve as a celebration in memory of Steven Keating, an inspiring advocate for patient data access. You can read extended details about this effort on our site (including more about Steven, our timeline, and calendar of events).
We held our first community call on December 10th – many thanks to the attendees and invited presenters, Karolina Alexiou and Rogier Koning! Future community calls will be held on the second Tuesday of each month.
Invited guest: Rogier Koning, Nobism, and Cluster Headaches
Rogier shared the Nobism app and data source in Open Humans, which he created to track symptoms, potential triggers, and treatments. Cluster headaches are one of the most painful things people can experience – they’re called “suicide headaches” – and patients understandably want to understand how to anticipate and reduce their own symptoms!
Rogier’s reports showed compelling visualizations produced with the Ubiqum project, which members can share their data with – illustrating how headaches occur over the course of months, at different times of the day – different individuals had different patterns for what time headaches were likely to occur. The effect of medications could be clearly seen in the patterns on the graphs!
One of our long-time community members, Ben Carr, noted he’s also a cluster headache patient, and reflected on his use of the app! He reflected on potential improvements and hadn’t realized he could also join the accompanying Ubiqum project. (Showing us there’s a potential need for prompting people!) Rogier also explained that the app isn’t limited to cluster headaches, and he’d welcome other chronic disease patients using it for new purposes.
Rogier has plans to expand community aspects of his work, and hopes to share more in the future!
Invited guest: Karolina Alexiou and GitHub data import
An analysis example from the GitHub data notebook: a word cloud generated from commit messages
In addition to the data import itself, Karolina demonstrated how this data can be visualized and what can be learned from it, by running a Personal Data Notebook on her own data. This notebook is already publicly available, so if you are using GitHub and want to give it a try, you can start right away.
Data Types & Uploading files
Mad & Bastian shared some ongoing work on the Open Humans end. While data sets are currently organized by the data source that has uploaded them, this sometimes makes sharing the data complex. Either because multiple projects upload the same or very similar data types (e.g. genetic data from different sources), or because a single data source uploads multiple kinds of data (e.g. activity tracking data that contains both step counts and GPS records). As Ben Carr noticed on the call, this can make granular sharing hard.
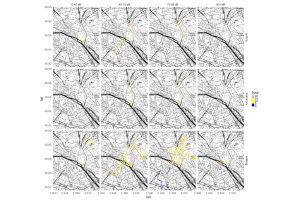
Bastian’s noise mapping, split by movement type (cycling, stationary, walking).
To adjust for this, Mad has been working on a data type system, which allows individual data files be classified according to the kind of data in them, instead of just relying on the source. They presented a new uploader tool for Open Humans, that can assign the data type to each file upload. Based on this, Bastian presented how this data can be used to upload environmental noise data, as recorded from an Apple Watch and how it can be explored through a Personal Data Notebook. One thing Bastian learned was that some of his noisiest times were at home; when he looked into it more closely, it was when he was in the shower!
Further discussions
Additionally, the participants of the community call discussed their experiences with tracking blood sugar through Continuous Glucose Monitors, how to make the Personal Data Notebooks more user friendly and whether it is possible to allow access to data without sharing the data sets themselves by allowing analyses being run in the cloud. Exchanging community member experiences and what they are working on was inspiring.
If you want to participate in the next community call please see our Community Call information & notes document for event details, it will be 14th of January at 10am PST / 6pm GMT.
In the last few weeks our community has launched a plethora of new projects that you can join to collect more data about yourself as well as new research opportunities covering topics from the genetics of personality over blood pressure tracking to cluster headaches. Find out more about those projects below:
QCycle: Tracking ovulatory cycles
QCycle is a participatory research study that follows the spirit of the Quantified Self. As a collaboration between Azure Grant at the University of California, Berkeley and all participants, the study is interested in mapping the diversity of biological rhythms such as the ovulatory cycle through different wearable devices such as the Oura Ring. In the long-term one of the aims could be creating open-source ovulation predictions.
The cluster headache patient community around Nobism has been particularly active in the last few weeks. Under the lead of Rogier Koning , the community was awarded one of the Open Humans project grants. The grant allowed them to integrate a data synchronization into their mobile application for tracking symptoms and interventions. Check out their app for iOS and Android.
Thanks to a collaboration with the Ubiqum Code Academy you can already use the data collected by the mobile apps to get personalized reports and data visualizations. In the Nobism Ubiqum Cluster Headache Project a team of data science students will create evolving, monthly reports based on the data you collect.
snps is a new open source Python package that aims to help users interact with genetic data from a variety of sources, including direct-to-consumer (DTC) DNA testing companies and whole genome sequencing (WGS) services. Specifically, snps provides tools to help with reading, writing, merging, and remapping SNPs.
The initial snps capability was developed by Andrew Riha as part of lineage, which joined the Open Humans ecosystem as a project in early 2019. Soon thereafter, numerous members from the Open Humans community, including Bastian Greshake Tzovaras, Mad Price Ball, James Turner, Ben Carr, and Beau Gunderson, requested support for VCF files. So, in May 2019, Kevin Arvai (with his VCF experience from Imputer) and Andrew teamed up to add the VCF capability, and wanting to share the work with others, snps began as an open source project to further enable citizen science.
Moreover, snps attempts to detect the assembly, or build, of the data. Commonly, Builds 36, 37, and 38 are used today, and these represent the “version” of the reference genome.
Writing
snps supports writing SNPs to CSV and VCF files for Builds 36, 37, and 38. This also means that snps can be used to essentially convert files from DTC DNA tests to VCF format.
Merging
snps supports merging datasets, e.g., if test results are available from more than one source. When SNPs are merged, any discrepancies are identified.
Remapping
snps supports remapping SNPs from one assembly to another. SNPs can be remapped between Builds 36, 37, and 38.
Two of our project grant awardees – Kevin Arvai and Andrew Riha – have been working tirelessly to build two new web tools that can make use of your genetic data that’s stored in Open Humans in interesting ways. And their hard work has paid off: Kevin’s Imputer and Andrew’s Lineage are now available!
Imputeris designed to fill the gaps in your genetic testing data. Direct-To-Consumer companies like 23andMe usually genotype just a small fraction of your genome, focusing on generating a low-resolution snapshot across your whole genome. Genotype imputation fills in those gaps by looking at reference populations of many individuals who have been fully sequenced in a high resolution, using this data to predict how to fill the gaps in your own data set. Imputer is using the reference data from the 1000 Genomes Project to perform this gap-filling and deposits the filled-up data in your Open Humans account. Kevin also provides two Personal Data Notebooks that you can use to explore your newly imputed data set. If you want to explore the quality of the newly identified variants, you can use this quality control notebook. And if you’re interested to see where your genome falls within a two-dimensional graph of different populations from around the globe, this notebook allows you to explore how closely you relate to other people in the 1000 Genomes data.
Andrew’s Lineage brings some further tools and genetic genealogy methods to Open Humans. If you have been tested by more than one Direct-To-Consumer genetic testing company, Lineage allows you to merge those different datasets into one large file, while also highlighting the variants that came out as different between those tests. You can also lift your files to a newer version of the human reference genome, which might be needed for using your data with other tools. Furthermore, Lineage brings a lot of interesting genetic genealogy tools: It allows you to compute how much shared DNA can be found between your own data and the genetic data of other individuals, using a genetic map. You can then create plots of the shared DNA between those two data sets, determine which genes are shared between them and even find discordant SNPs between the data sets.
I’ve recently joined the board of directors of Open Humans, joining the current board along with two other new directors, Marja Pirttivaara and Alexander (Sasha) Wait Zaranek. I’m honored to be in their company, and I want to take advantage of joining the board to explain how, in my view, Quantified Self and Open Humans fit together. Both communities include many people working in science and technology who take an interest in biometric data. But this isn’t enough to define a common purpose, and in fact a much deeper connection between Open Humans and Quantified Self has developed over the last few years, as each community has approached, from nearly opposite directions, a common problem: How can we make meaningful discoveries with our own personal data?
Sample projects from Open Humans, an open infrastructure for storing and sharing personal data with chosen collaborators.
Open Humans has its roots in the Personal Genome Project,
whose purpose was to supply scientists with human genomic data so that
they could make discoveries more quickly. The geneticist George Church
created a project to sequence the genome of individual volunteers who
agreed to donate their genomic data non-anonymously, creating a common
data resource. Since many important genomic questions cannot be answered
with genome data alone, volunteers also shared other information about
themselves. The Personal Genome Project inevitably became a somewhat
more general personal data resource for science; however, with its focus
on genomic data, much relevant data, including the kind of data that
could be collected in daily life, remained out of scope.
When I first met Jason Bobe, who co-founded Open Humans with Mad Price Ball,
he was keenly interested in this question of how to connect personal
genomes with other personal data sets. Jason had worked with George
Church on the Personal Genome Project. He and Mad saw Open Humans as an
analogous effort, but one that would allow volunteers to contribute any
kind of data. The Personal Genome Project was now a decade old. Perhaps,
with deep personal data sets to work with, scientists could deliver on
the promise of genomics to revolutionize medicine, a promise that had
been long frustrated by the complexity connecting genomic data with real
world outcomes.
I understood the goal. A few years earlier, I’d written a long Wired story about the taxonomic collaboration between Daniel Janzen and Paul Hebert.
Janzen, along with his other accomplishments, was among the world’s
most knowledgeable field biologists. Hebert had developed a genomic
assay that promised to identify animals using an extremely small region
(about 650 base pairs) of their mitochondrial DNA. Hebert was confident
in his technique, but needed to prove its utility. How could the genomic
data he was collecting be paired to real world ecological knowledge? At
their field station in the Guanacaste Preserve in Costa Rica, Janzen
and his partner Winnie Hallwachs, along with their students and
colleagues, collected hundreds of butterflies and moths, identified
them, snipped off a leg, and shipped it to Guelph, a city in Canada,
where Hebert ran the sequence. Slowly, painstakingly, they connected the
genomic data to the real world data. More than just proving that
Hebert’s technique worked, they also brought a new degree of resolution
to the ecological picture; showing, for instance, that individual
specimens, though visually almost identical as adults, may belong to distinct evolutionary clades and feed on different plants.
In my first conversations with Jason, I saw this as how Open Humans
should work. It promised to provide the “field biology” for the genomic
studies of the Personal Genome Project.
Handwritten species list from the Patilla field station in the Guanacaste National Park, Costa Rica.
Unfortunately, as attentive readers, link followers, and experts in
the history of overconfidence in science may already have realized,
there’s a pretty serious flaw in my analogy. Paul Hebert was using the
genome to distinguish strands in evolutionary history, mostly at the
level of species. He wanted to know, given a leg, what kind of creature
it was from. Answering relevant health questions requires understanding
the world at a far more detailed level, down to extremely small
differences among individuals of the same species. The trick that Hebert
used is never going to work; and, for many of the health related
questions we care about, nobody knows the tricks that will work. Fifteen
years after the launch of the Personal Genome Project, it continues to
supply data resources to basic science, but its relevance to medicine
remains mostly a promise.
In the Quantified Self community the focus has always been on
individual discovery: How can we learn about ourselves using our own
data? Many of the questions addressed by people doing their own QS
projects relate to health and disease. Browse the archive of Quantified Self Show&Tell
presentations and you’ll find projects on Parkinson’s disease,
diabetes, cognitive decline, cardiovascular health, depression, hearing
loss, and many other health related issues. The kind of “everyday
science” practiced in the Quantified Self community can be understood as
being the opposite of the genome-wide association studies. Instead of
finding small, telling differences among groups of people, the everyday
science of the Quantified Self finds large effects within a single
person who is both subject and scientist.
This comes with its own kinds of difficulties. People doing
Quantified Self projects related to health face a number of discouraging
barriers, including lack of access to their own data and medical
records, bureaucratic roadblocks and exorbitant costs in ordering their
own lab tests, problems in acquiring the requisite domain knowledge to
test their ideas and interpret their data, and – perhaps most
discouraging to people who are dependent on medical professionals for
some aspect of their care – lack of recognition in the health care
system that self-collected data can be useful for making decisions about
treatment.
In the 11 years since Quantified Self started, participants have
tried many different ways to overcome these barriers, both individually
for their own projects and systematically through creating tools and
advocating for better policies. One of the lessons from this work is
that while the focus of self-tracking projects is typically on
individual learning, the methods required to make sense of our data
often require collaboration. Existing systems are not designed to
provide support for the kind of highly individualized reasoning we do;
therefore, we have to build a new system. Key requirements of this new
system include: private, secure data storage; capacity to integrate data
from commercial wearable devices; fine-grained permissions allowing
sharing of particular data with particular projects, and withdrawal of
permission; capacity for ethical review both to protect individual
participants and to enable academic collaborations.
Two years ago, we organized our first participant-led research
project in the Quantified Self community. A group of about two dozen of
us measured our blood cholesterol as often as once per hour, exploring
both individual questions about the patterns and causes of variation in
our blood lipids and a common group question about lipid variability. We
had a pressing need for some collective study infrastructure, but there
was no available tool that worked for our needs. We took a DIY approach
and at the end of the project we’d learned a tremendous amount both
about our own varying cholesterol and about the process of self-directed
research. (Our paper, “Approaches to governance of participant-led research,”
has recently been published in BMJ Open; our paper on our collective
discovery about lipid variability has been accepted for publication in
the Journal of Circadian Biology; we’ll add a URL when we have it.)
Slide detail from one of Azure Grant’s QS Show&Tell Talks
At the conclusion of our study, one of the participant organizers
Azure Grant, decided to press ahead with another participant-led study
on ovulatory cycling. Azure had already presented a self-study on using continuous body temperature to predict ovulation
at a Quantified Self conference. Now, she wanted to organize a group of
self-trackers to try something similar, but integrating newer
measurement tools to acquire higher resolution data. Among these tools
was the new version of the Oura ring,
which offered body temperature, heart rate, and sleep data. This idea
put new demands on our study infrastructure. Thanks to generous
collaboration from Oura engineers, we could offer participants access to
detailed data from their rings. But how could this data be stored
privately and controlled by each individual, while also being available
using fine-grained permissions to their fellow participants and study
organizers? How could this data be integrated with other data types they
might decide to collect during the project? Where was there
infrastructure for a “field biology” of the self?
We turned to Open Humans. The personal reasons were as important as
the technical ones. Mad Ball, along with her work leading Open Humans,
is a long time participant in the Quantified Self community, who has
consistently advocated for non-exploitive approaches to handling
personal data, and has contributed the results of her own self-directed
research. (See Mad’s recent talk on “A Self-Study Of My Child’s Genetic Risk.”) And Bastian Greshake Tzovaras, the Open Humans research director, quickly proved to be an extremely sensitive and skilled collaborator. Bastian co-founded openSNP,
a grassroots effort that outgrew Personal Genome Project by supporting
citizen science participation. (Currently, there are more genotyping
datasets publicly shared in openSNP than all other projects in the world
combined.)
With help from Mad and Bastian and the Open Humans infrastructure, we
built our next stage study workflows with encouraging speed and
harmony. Fundamentally, we found ourselves aligned on the core idea that
research processes designed around personal data sets should be built
to protect individual agency, even where this requirement creates
friction for academic collaborators. The rarity of this commitment may
only be obvious to those few people who have gotten painfully deep into
the workflows of study infrastructure. (And I recognize that a post of
this length that is this deep in the weeds can have very few readers!)
But, in a way, that’s one of the beautiful things about this stage of
building a new knowledge infrastructure. We’re far into it enough to
have evidence that we’re on the right track. But we’re still close
enough to the beginning that each step is a significant contribution and
a potential model to build on.
I very much hope that over time – and the sooner the better – our
shared ideas about individual agency and everyday reasoning are embodied
in tools and policies that are so commonplace that no single
organization is responsible for them. But for now, it’s impossible not
to recognize that Open Humans is an indispensable resource, defining an
approach that needs to be developed and expanded, and managed by a team
that has deep insight into the challenges and potential of participatory
science. I look forward to building more connections between our two
communities.
I’m thrilled to announce the results of our 2019 elections for the Open Humans Foundation Board of Directors!
Our community seat winner is Marja Pirttivaara, and our board-elected seats are Gary Wolf and Sasha Wait Zaranek.
Marja Pirttivaara: When I first met Marja at the MyData conference in 2018, it was wonderful to find a like-minded soul — between her interests in genetics and in empowering individuals with their personal data. Marja generously agreed to our EU representative for GDPR, and it’s been exciting to see our project become more global.
Gary Wolf: As co-founder and director of Quantified Self Labs, Gary has supported numerous citizen scientists in their quest to use their personal data to understand themselves, and to collectively create new knowledge. His work is strongly aligned with that of Open Humans, and we very much looking forward to his contribution and leadership.
Sasha Wait Zaranek: Sasha is one of the founders of the Harvard Personal Genome Project and continues to lead in this area. Their focus is on genome data: they want to see that data managed by the people it came from, more understandable, and more re-usable for new projects — and they want to help Open Humans make those things happen.
Marja, Gary, and Sasha join our ongoing board members: Mad Price Ball, Karien Bezuidenhout, Steven Keating, Dana Lewis, and James Turner.
We must bid farewell to Misha Angrist and Michelle Meyer — their terms have ended. Both have been involved with the organization for many years, and we hope this is not the last we see of them! We must also bid farewell to Chris Gorgolewski, who has resigned; his 2018 seat is being left vacant for now. Also, we’ve made the voting results from the 2019 Community Seat election available here: http://openhumansfoundation.org/2019-ohf-election-votes.csv
We’re honored by the contribution of every board member, and their collective stewardship of our project. And we’re honored by all candidates for these positions. Not everyone can win — indeed, it would be a poor election if we didn’t have people to choose between. We very much hope other candidates remains involved — there are so many things to do together!
 In case you missed it: we took notes & recorded our kickoff webinar for the
In case you missed it: we took notes & recorded our kickoff webinar for the