
We got a great selection of new projects and personal data explorations for you as an end-of-year gift. Here is an overview of the data import projects recently launched on Open Humans:
- Oura Ring: You can now explore your sleep habits, body temperature and physical activity data as collected by the Oura Ring.
- Overland: If you are using an iPhone you can now use Overland to collect your own geo locations along with additional data such as your phone’s battery levels over the day.
- Google Location History: As an alternative way to record and import your location data you can now import a full Google Location History data set.
- Spotify: Start creating an archive of your listening history through the Spotify integration
- RescueTime: Import your computer usage data and productivity records into your account
Read more details about those integrations below:
Connect your Oura Ring
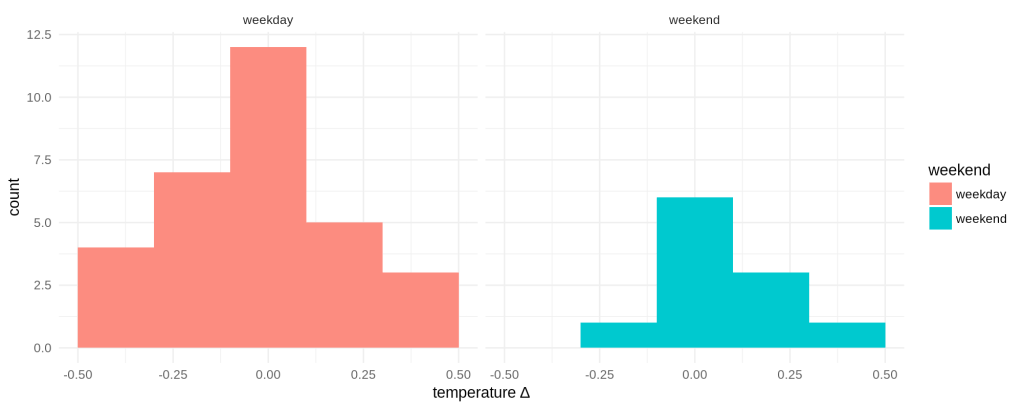
The Oura is a wearable device well hidden inside a ring. It measures heart rate, physical activity and body temperature to generate insights into your sleep and activity habits. With Oura Connect you can setup an ongoing import of those data into your Open Humans account. This allows you to explore those data more thanks to already available Personal Data Notebooks!
Map your own locations with Overland
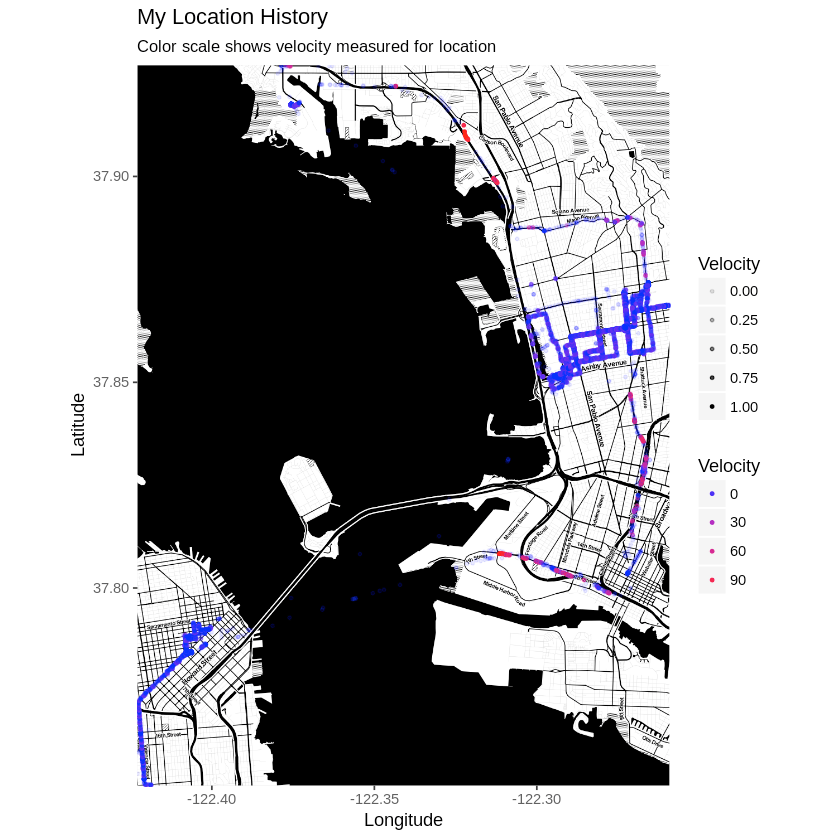
Overland is a free and open-source iOS application that keep track of your location through your phone’s GPS along with some metadata like velocity and the WiFi you are connected to. With Overland Connect you can import these data into your Open Humans account. The data can be visualized through Personal Data Notebooks, used to display your current location through a Personal API or to Geo-Tag your photo collection!
Use Google Location History to explore your location data
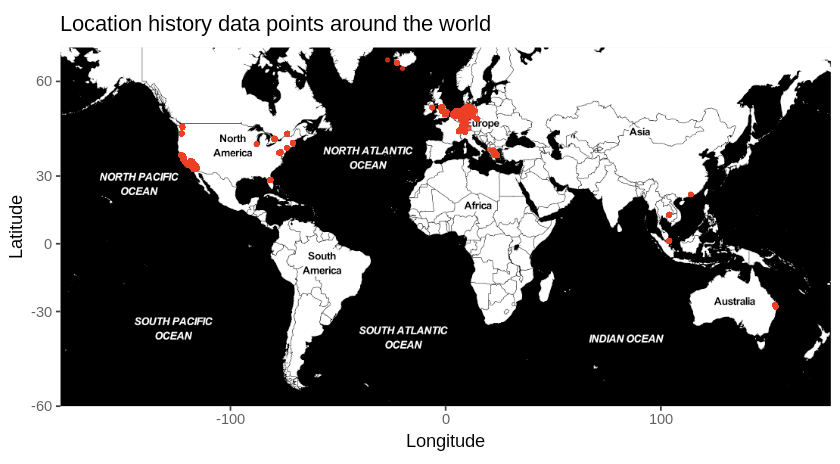
Thanks to our Outreachy interns we have another new geolocation data source: Google Location History. No matter if you are using an iPhone or an Android phone, you can use the Google or Google Maps app on your phone to record where you have been. Through Google Takeout you can now export this data and then load it into Open Humans and explore it through Personal Data Notebooks.
Explore your music listening behaviour with Spotify data
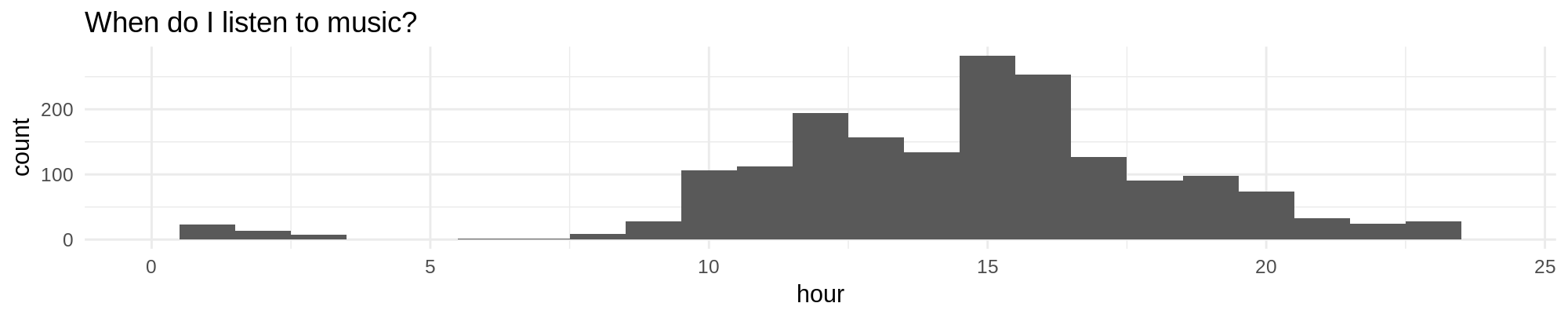
Another Outreachy intern project was to collect your Spotify Listening History through Open Humans. Using Spotify Connect will automatically import the songs you listen to along with lots of metadata (e.g. how popular was the song at the time you listened to it?). Once you have collected some data, you can explore these through another Personal Data Notebook!
Learn about your productivity with RescueTime
RescueTime is a service that collects how you are using your computer through a data collection app on your computer. It keeps track of the apps you use and the websites you visit and classifies these as productive or unproductive time (Hello Facebook!). Thanks to a personal project by Bastian you can import this data into your Open Humans account and explore it through Personal Data Notebooks
With this the whole Open Humans team wishes you a happy personal data exploration, relaxed holidays and a wonderful start of 2019!



We are happy that Open Humans will have four Outreachy interns this summer. Our interns are working on their own Open Humans related projects and will regularly blog about their internship experience. Read Rosy’s post about creating an app to manage your Open Humans project: