About the authors: Mad Price Ball and Bastian Greshake Tzovaras lead Open Humans as Executive Director and Director of Research, a nonprofit project dedicated to empowering individuals and communities around their personal data, to explore and share for the purposes of education, health, and research. We have other diverse work in open science, data technology, digital and research ethics, health and humans subjects research, and citizen science. We’ve been thinking about this for a while now: What can be built to make collaboration a reality in self-research?
Gary Wolf’s call for enabling individual discovery describes a vision we also share: we believe in the untapped potential of people studying themselves. Answering questions relevant to their own lives, with motivations ranging from chronic disease to curiosity. We encourage you to read what he’s written: “How to Make 10 Million Discoveries”
We can all ask questions about our lives: sometimes unique, sometimes common. “Does this medication help me? Do I say “sorry” too often? Is social media making me unhappy?”
Each of those questions is a potential discovery – about you.
Gary wrote: “My colleagues and I envision a world with as many new, consequential health discoveries as there are articles in Wikipedia.” That is, ten million discoveries.
We think this can be done, and we’ll tell you how.
(And if you’re interested in helping – skip to the bottom to read how!)
Doing things together
“If you want to go fast, go alone. If you want to go far, go together.”
Until recently, people would have told you it’s impossible for hundreds of thousands of volunteers write the world’s largest encyclopedia in nearly 300 languages. Wikipedia now exists. It is an inspiring example of the potential of “peer production”: the idea that people can co-create knowledge in a collective way, with an open collaborative approach. It is made possible by the Internet – by online methods for knowledge-sharing, re-use, and decentralized coordination.
Could this work with self-research? Gary observed the potential:
“Technology that makes it easy for people to make, discover, and share things has fundamentally reshaped older systems of mass production in many domains. Why not in health? The diversity of needs and questions people have, and the diversity of skills and experiences required to address them, makes this a natural job for peer production. Healthcare may be slow in helping. But we can help each other.”
Few of us can become an expert in everything we need when studying ourselves. This is something peer production can solve. The outcome is incredibly powerful: people can contribute in the place they are expert, and benefit from the expertise of others.
Imagine a world where someone produces an analysis of their data – and then shares it in a way others can easily use to analyze their own data.
Imagine a world where someone produces a tool to collect data – and then shares it in a way others can easily use to collect their own data.
Even more – imagine the power if these are done in “open” ways – where analysis code can be remixed to answer a new personal question, where an app or hardware tool can be repurposed to collect the data you need.
Imagine a place where people shared their remixes. Their methods for putting the pieces together. Their ideas.
This isn’t pure fantasy: we’re already part way there! The card10 badge that Gary discusses – a device self-trackers might use – is an open hardware project that has produced scores of open source apps. In Open Humans, we have scores of open source notebooks you can use to analyze diverse personal data. In the Quantified Self forums, there is a growing set of “project logs” where people share self-research as they do it.
What’s missing is a synergistic connection for the parts: a thriving community of co-creators.
What’s left to build
The answer is, to us, deceptively simple: we need better communication.
We need to connect people more: to share personal projects and tools and ideas, to engage and help each other, to form groups that share our interests. There are already many solutions for how to go about self-research. What we really need is a place where we can learn about, use, and adapt the things that already exist and have already been done. We need something that promotes peer support and collaboration through communication, sharing, contribution, remix, and re-use.
We should make those things easy and rewarding. Doing research about ourselves needn’t be a self-centered task: when we share our solutions and experiences and discoveries, that can have value to others. We can become part of something larger than ourselves.
To be clear: there is more needed than “building a platform”. It needs communities using it. Self-research needs to be do-able. Gary’s vision of ten million discoveries requires aligned work in the tools, the methods, and in communities that want it – things other stakeholders in the Article 27 effort represent.
We’re not alone in seeing the missed opportunity. A recent paper about the Quantified Self community (Heyen 2019) reflected:
“it is noticeable that, so far, no knowledge accumulation can be observed in the QS movement, nor has a common stock of knowledge developed (yet). This is certainly also due to its rather loose form of networking. […] …each self-tracker starts more or less from scratch, regardless of whether another self-tracker has already worked on exactly the same question and gained insights that could be built upon. Correspondingly, public presentations of self-tracking research at meetups or conferences make hardly any references to other self-trackers and their activities. In this respect as well, personal science is a very self-related affair.” (emphasis added)
What’s missing isn’t merely new solutions – but, more importantly, connecting people who create and use them. A place where new solutions are created and shared and improved upon.
This is entirely doable. One of the most powerful aspects of the Internet is that it connects us.
What you can do
We want to build this, and we need to prototype. You can help.
Can you do a self-research project together with us?
We’re calling for people to work together in the coming months to do a set of self-research projects together. If you’re interested in being part of the group, get involved!
You can…
We are hoping this effort will be, in part, a memorial. Last year we lost Steven Keating, a member of our board, to brain cancer. Curiosity was a driving force in Steven’s life, and he was an inspiring advocate for patient data access. He recorded and shared videos of his brain surgery, explored his cancer’s genetic data, and printed 3D models of his tumor.
In his memory, we would like to help more people make discoveries about themselves. What we do in coming months has the potential to seed an ongoing community.
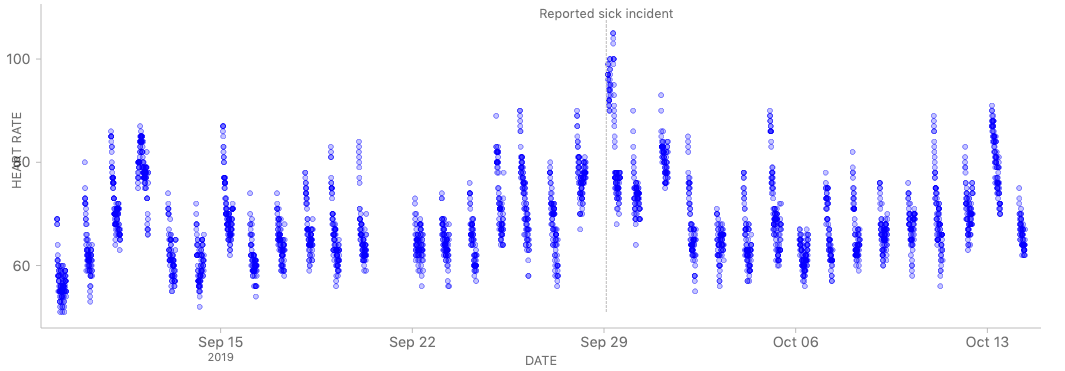
 In case you missed it: we took notes & recorded our kickoff webinar for the
In case you missed it: we took notes & recorded our kickoff webinar for the